Key Takeaways
- Outliers, extremely high or low values of a continuous variable are common in survey data. They can be atypical but valid observations (e.g., a productive household reporting a large quantity of maize harvested) or the result of data collection or processing errors.
- Appropriately handling outliers can reduce their distortion of summary statistics or analytical results, and transparency around methods can support reproducibility.
- The outcome of an outlier treatment method depends on the type of measurement error that generated outlier observations, the overall sample size, the subgroups of interest, and the degree of variation across those subgroups.
- We developed a simple tool to explore the consequences of different methods, using household survey data from the LSMS-ISA.
The outlier problem in survey datasets
Outliers in survey datasets can represent valid observations when they reflect truly
atypical cases within the sample or population. However, many outliers arise from
errors. Three main types of errors can generate outliers:
-
- Response error: when respondents misstate their answer. For example, a household might report having harvested 1,000 grams of maize when they intended to report 1,000 kg.
- Recording error: when the enumerator incorrectly enters a response that still passes the data entry validation checks. For example, an enumeratorentering 10,000 kg of maize harvested while the respondent states 1,000 kg
- Derived values from plausible reporting: In some cases, the combination of otherwise plausible values can produce atypical outcomes. For example, a farmer reports harvesting 1,500 kg of maize on a 0.1-hectare plot, two individually plausible values that result in an atypically high estimated yield of 15,000 kg maize/ha – more than maize yields in most high-input agricultural systems and far above typical estimates for small-scale producers (SSPs).
If left unaddressed, outliers can meaningfully distort summary statistics, variable
distributions, and analytical results. In practice, treating outliers involves two sequential decisions: selecting a method to detect outliers and choosing how to handle those that are identified. Each of these methods has its own strengths and limitations. It is therefore important to understand the consequences of different outlier-handling approaches and to transparently document the chosen method when reporting statistics or conducting analyses.
Approaches to detecting outliers
There are several methods for detecting outliers, ranging from simple techniques that rely solely on the distribution of a given indicator to more complex model-based approaches that incorporate information from additional variables. Due to their simplicity, common use, and ease of implementation, in this post, we discuss three non-model-based approaches: i) percentiles; ii) median absolute deviation-based (MAD); and iii) transformation-based approaches. Table 1 describes each method and characterizes its strengths and limitations.
| Method | Definition | Threshold Selection | Distribution Assumption | Sensitivity and outlier considerations |
| Percentile | Classify all values above/below a specified percentile (threshold or cutoff) as outliers | None | Based on estimated outlier occurrence rates | Affects a predictable number (proportion) of observations that depends on the percentile threshold and whether trimming is at one or both tails. |
| Median Absolute Deviation | Classifies values whose absolute deviation exceeds a specified multiple of the MAD as outliers. MAD is the median of the absolute differences between each observation and the sample median. | Symmetric and typically normal | Commonly uses a multiple of MAD (e.g., 3-3.5*MAD) | Sensitivity and outliers depend on the clustering of observations close to the median and normality of the distribution. Enforces symmetry on the resulting distribution. |
| Transformation | Applies a transformation function and then classifies values to select outliers from the transformed dataset based on a z-score threshold. Examples include simple log or piecewise functions like Yeo-Johnson. | Non-normal, usually lognormal | Rule of thumb based on standard deviation/z-score (typically +/- 3 SD) | Depends on how closely the transformed distribution matches a normal one. Better for asymmetrically distributed data, may flag fewer outliers than the other methods. |
Approaches to handling outliers
Once outliers are identified, the analyst must decide whether to ignore them, delete them without replacement, or delete them and replace them with more plausible values. Dropping outliers from the dataset, a process termed trimming, involves an approach for detecting outliers (Table 1). Trimming without replacement reduces the sample size and could potentially bias the distribution if valid observations are removed. In small datasets, there is also a risk of reduced statistical power.
Alternatively, the analyst can replace the outliers with plausible values to maintain the original sample size (Table 2). Winsorization is a popular method that combines percentile-based detection of outliers (e.g. beyond the 99th percentile) with replacement at the threshold. It assumes that the “correct” value of the measurement being replaced is most likely near the tail. While this method reduces the influence of individual observations over the summary statistics, it can also lead to an increased concentration of observations at the threshold values and may have little practical effect if the threshold value is close to the outlier values. Median replacement is also an option that is often combined with the MAD outlier detection approach. Median replacement assumes that the proper value is closer to the center of the distribution. While it also reduces the overall variance of the data, it can potentially bias summary statistics such as the mean and standard deviation.
All three methods may fail to handle small (error-based) outliers in data with many valid zeros, such as when farmers lose their entire harvest.
| Method | Definition | Notes |
| Trimming without replacement |
Removes outliers entirely |
|
| Threshold Replacement |
Replaces the outliers with the values of the thresholds; typically used with percentile-based outlier detection (winsorization) |
|
| Median Replacement |
Replaces extreme values with the median |
|
How to choose?
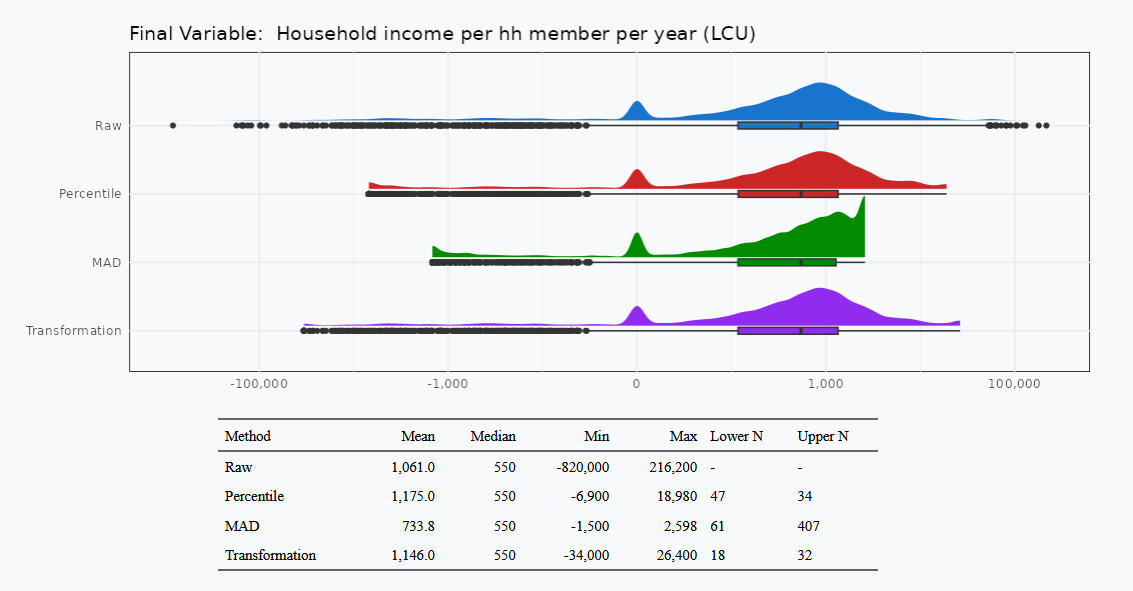
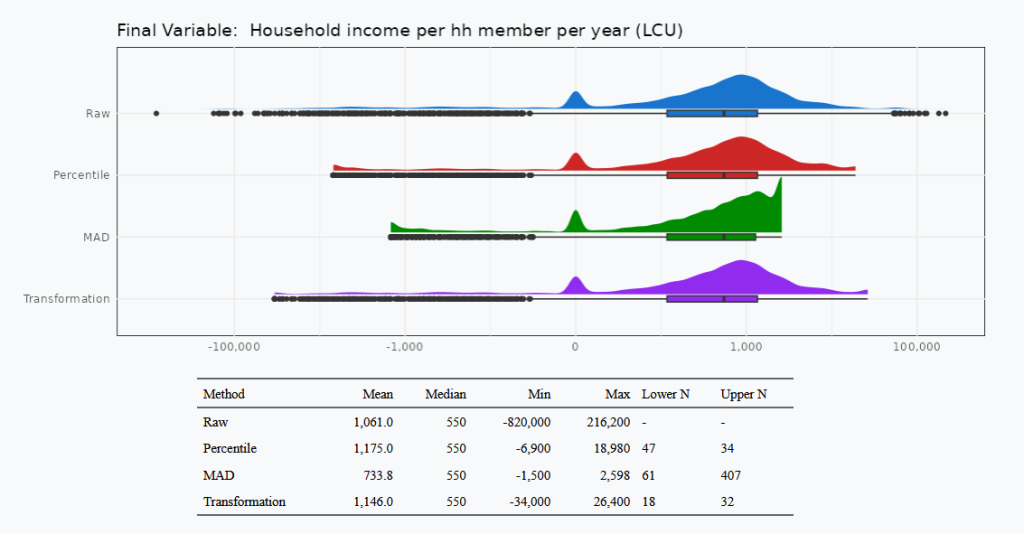
To support analysts comparing alternative outlier-treatment methods, we developed an interactive web-based tool implemented in R Shiny using several LSMS-ISA datasets, the Ethiopia ESS, Malawi IHS, Nigeria GHS, Tanzania NPS, and Uganda NPS. The tool allows users to select a dataset, variable, outlier-treatment method, and thresholds, and examine how these choices affect both the variable’s distribution and key summary statistics. An example using the tool is discussed below.
Example: Comparing the effect of outlier treatment methods on maize yields
To illustrate how different outlier treatment methods are applied, we use maize yield in Nigeria’s GHS wave 5 as an example. Yield is measured as the ratio of quantity harvested to area planted. It is a challenging indicator from an outlier management perspective because otherwise reasonable-seeming measurements of the numerator and denominator can produce extreme values when combined.
The raw data contain 1,109 observations. Maize quantity harvested ranges from 0 to 10,000 kg and area planted from 0.05-9.29 hectares[1], while yield ranges from 0.81 to 43,060 kg/ha. For quantity harvested, all methods reduce the top end of the distribution while leaving the bottom untouched due to the high prevalence of valid zeros (i.e. crop failure, roughly 4% of observations). Observations where the crop was not ready for harvest when the enumerators visited are removed.
| Method for detecting outliers | Thresholds | Number of observations identified as outliers | Difference in mean yield estimate between the raw data and the outlier-corrected data | ||||
|---|---|---|---|---|---|---|---|
| Quantity Harvested (kg) | Area Planted (ha) | Yield (kg/ha) | Replacement | Trimming Only | |||
| Percentile | Lower first and upper 99th percentile | 12 | 25 | 10 | -2.65% | -5.44% | |
| MAD | +/- 3.5*MAD | 126 | 169 | 140 | -17.9% | -12.2% | |
| Yeo-Johnson Transformation | +/- 3 SD | 4 | 0 | 3 | -0.48% | -4.11% | |
The large differences between methods results from the substantial right skew of the data, i.e., there tended to be more very small observations than very large ones, and most observations were close to the mean. For example, in area cultivated, the minimum (0.05) was closer to the mean (0.5) than the maximum (9.6), but the range of log-transformed data is more symmetrical (-2.30 to 2.99). Thus, large observations were more “expected” in the log transformed distribution than they were in the original distribution. This difference further illustrates how researcher expectations about the distribution of observations can shape data processing decisions. An assumption of lognormality, reasonable in a situation where a researcher anticipates a few observations where landholdings are significantly larger than the mean, suggests that most of the observations are within the expected range, whereas assuming that the sample should be more normally distributed (which occurs when employing MAD) produces a much greater number of outliers.
Practical recommendations for researchers
EPAR has developed outlier treatment guidelines relevant for common agricultural and rural development indicators derived from large-scale surveys such as LSMS-ISA, 50×2030, and India-NSSO datasets. We use percentile-based outlier detection with replacement at the thresholds (winsorization) at the top of the distribution, the bottom, or both. Before computing summary statistics, we identify outliers using the 1st and 99th percentiles of the indicator’s distribution. We then replace non-zero values above or below those thresholds with the threshold values (Figure 1). For indicators that are constructed as a ratio of other indicators, such as yield, we first winsorize the numerator and denominator, then compute the ratio using the winsorized values, and then winsorize the final indicator. To ensure opportunities for comparison, we provide both winsorized and un-winsorized variables.
Because it is impossible to know what the actual population distribution is, we consider the validity of the approaches given our knowledge of the system, whether they are consistent when applied to multiple rounds of data collection, and whether they align with trusted and available outside data sources. In this example, the most “realistic” maximum yield is produced by the percentile method that produces maximum yield estimate of 18,000 kg/ha that is still technically feasible though uncommon. With MAD the maximum yield estimate in the outlier-free distribution is 4,500 kg/ha and is substantially lower than what some highly successful small-scale producers achieve. After the transformation method is applied, there are still observations with yield estimates of 32,000 kg/ha that are likely not achievable even on highly productive and carefully cultivated plots. The percentile method was also in the middle in terms of outliers identified (MAD flagged over 10% of the dataset as outliers).
When considering consistency across datasets, comparisons across all five Nigeria LSMS-ISA GHS waves show greatest alignment between the percentile and transformation methods, whereas MAD tended to underestimate yield compared to the other two methods depending on survey wave. Finally, in terms of aligning with outside observations, the UN FAO’s FAOStat service provides or estimates national level crop yields, typically drawn from administrative data. Unfortunately, substantial differences between FAOStat and the GHS, including differences in the sampled population and data collection methods, suggest the analyst may need to look for alternate cross-validation estimates.
Overall, outlier control results in a negligible (~ -1%) to substantial (~ -20%) revision to yield estimates. At the household level, the absolute differences seem small, but the difference in the total national harvest ranges from 9.6 to 13.5 million tons – a large range for policymakers to consider. Given that the mean household is farming an estimated half-hectare of maize, the range equates to a 50-kg difference in harvested quantity, roughly equivalent to the annual consumption of 1.5 people.
In the context of maize yield in Nigeria, MAD lowered the mean the most, the transformation method the least, and the percentile method was somewhere in between. The choice of replacement or trimming had a substantial impact on the variable mean.
| Detection Method | Replacement / Trim | Mean (kg) | Median (kg) | Min (x!=0) (kg) | Max (kg) | # obs addressed (lower tail) | # obs addressed (upper tail) |
| Raw Data | 725.2 | 400 | 0.65 | 10,000 | – | – | |
|---|---|---|---|---|---|---|---|
| Percentile | Tails | 705 | 400 | 0.65 | 5,384 | 0 | 12 |
| Trim | 624.1 | 400 | 0.65 | 5,000 | 0 | 12 | |
| MAD | Median | 455.5 | 400 | 0.65 | 1,500 | 0 | 126 |
| Trim | 379.4 | 270 | 0.65 | 1,500 | 0 | 126 | |
| Transformation | Tails | 723.2 | 400 | 0.65 | 8,100 | 0 | 4 |
| Trim | 693.7 | 400 | 0.65 | 8,100 | 0 | 4 |
| Detection Method | Replacement / Trim | Mean (kg) | Median (kg) | Min (x!=0) (kg) | Max (kg) | # obs addressed (lower tail) | # obs addressed (upper tail) |
| Raw Data | 0.4937 | 0.28 | 0.05 | 9.29 | – | – | |
|---|---|---|---|---|---|---|---|
| Percentile | Tails | 0.484 | 0.28 | 0.054 | 3.55 | 15 | 10 |
| Trim | 0.449 | 0.28 | 0.054 | 3.26 | 15 | 10 | |
| MAD | Median | 0.305 | 0.28 | 0.05 | 0.883 | 0 | 169 |
| Trim | 0.294 | 0.24 | 0.05 | 0.794 | 0 | 169 | |
| Transformation | (No outliers detected) | – | – | – | – | – | – |
| Detection Method | Replacement / Trim | Mean (kg) | Median (kg) | Min (x!=0) (kg) | Max (kg) | # obs addressed (lower tail) | # obs addressed (upper tail) |
| Raw Data | 1,469 | 670 | 0.81 | 43,060 | – | – | |
|---|---|---|---|---|---|---|---|
| Percentile | Tails | 1,430 | 740 | 0.81 | 18,020 | 15 | 10 |
| Trim | 1,389 | 770 | 0.81 | 17,770 | 15 | 10 | |
| MAD | Median | 1,206 | 930 | 0.81 | 4,512 | 0 | 140 |
| Trim | 1,290 | 930 | 0.81 | 4,728 | 0 | 140 | |
| Transformation | Tails | 1,462 | 670 | 0.81 | 32,680 | 0 | 3 |
| Trim | 1,411 | 670 | 0.81 | 32,680 | 0 | 3 |
Explore More
Blog written by Andrew Tomes, Didier Y. Alia, and C. Leigh Anderson
Citation: Tomes, A., Alia, D.Y., & Anderson, C.L. “Outlier Treatment in Continuous Indicators: Blog series – Choices with Consequences”, University of Washington, Evans Policy Analysis and Research Group (EPAR), published June 10, 2026. <https://epar.evans.uw.edu/choices-with-consequences-1-outlier-treatment-in-continuous-indicators/>